본 챕터에서 다룰 내용 :
1. 롤링 업데이트란?
2. 지시적 업데이트
3. 선언적 업데이트
4. 롤아웃 제어
업데이트 전략
어플리케이션은 변하기 마련이고, 이에 따라 이미 배포한 파드도 업데이트가 필요하다. 일반적인 운영 환경이라면 두가지 시나리오를 생각해 볼 수 있다.
재생성 (=Recreate)
삭제 후 교체한다. 1) 기존 운영중인 파드를 모두 내리고 2) 새로운 파드를 동시에 생성한다. 이 방법은 상대적으로 깔끔하다. 데이터가 꼬일 일도 없고, 사용자가 새로고침 할 때 마다 다른 버젼의 서비스로 접속하는 혼선을 원칙적으로 차단한다. 하지만 이 방식은 결정적으로 다운타임이 발생한다. 요즘의 "무중단" 트랜드와는 맞지 않다.

블루 그린 디플로이먼트
1) 먼저 새로운 파드를 모두 생성하고 2) 서비스(외부로 노출하는 네트웍)의 endpoint를 일순간에 기존 파드에서 새로운 파드로 변경하는 방식이다.
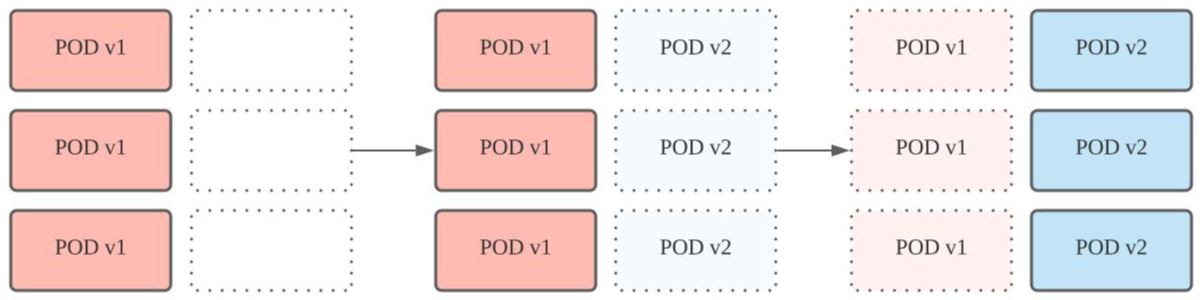
새 파드가 모두 준비가 될 때 까지 기존 파드를 서비스와 연결하여 서비스를 하다가, 모든 새 파드가 준비되면 서비스의 연결을 새 파드로 변경하므로 무중단 서비스를 제공할 수 있다. 이후 기존 파드를 비롯한 원래 자원을 모두 삭제할 수 있다. 이 방법은 무중단 서비스를 유지하면서도 상이한 버젼의 서비스가 혼란스럽게 제공되는 현상을 근본적으로 차단한다. 하지만 이 방법은 2배수의 파드를 잠깐이라도 기동하기 위해 2배의 자원이 필요하다는 단점이 있다.
롤링업데이트
기존 파드와 새 파드를 공존하면서 점진적으로 교체하는 기법이다.
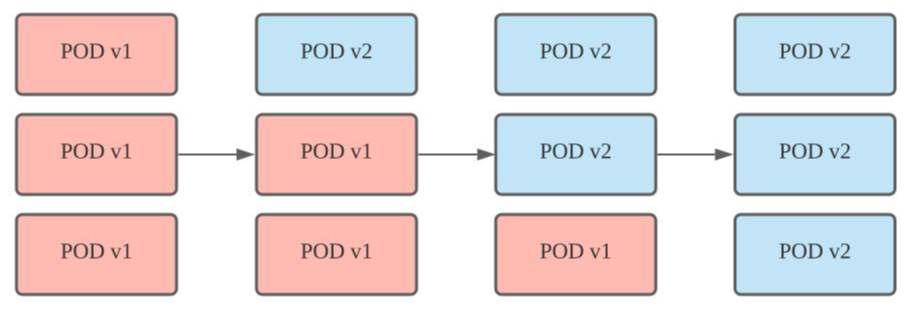
이 방법은 무중단 서비스를 구현하면서, 추가 자원을 많이 필요로 하지 않는다는 장점이 있다. 하지만 모든 파드를 교체하기 전 까지 두개의 버젼이 공존한다. 따라서 하위 호환 / 상위 호환을 제공할 수 없는 서비스에 적용은 적합하지 않다. 이후 설명하는 모든 내용은 이 롤링업데이트를 기준으로 한다.
지시적 업데이트
참고.
영어 원문은 "imperative", 번역서에서는 "명령"적으로 기술하고 있다. imperative의 사전적 의미가 order 이며, 우리말에서 order를 지시로 번역하기도 하므로 여기서는 어감을 이쁘게 하기위해 지시적 업데이트라고 기술한다.
참고.
원문에는 kubectl rolling-update 를 설명하는 챕터지만, 해당 명령은 2021년 기준으로 dprecate 상태이다. 따라서 기존 rolling-update의 문제점과 ReplicationController를 직접 제어할때의 한계를 기술한다.
"rolling-update" 명령
2021년 현재는 deprecate이지만 이전 버젼의 쿠버네티스에서는 kubectl rolling-update 명령을 지원하였다.
// ReplicationController kubia-v1을 대신하여, {account}/kubia:v2를 실행하는
// ReplicationController kubia-v2를 만든다. kubia-v2 배포를 종료하면 kubia-v1은 삭제한다.
$ kubectl rolling-update kubia-v1 kubia-v2 --image={account}/kubia:v2이 방법은 control-plane 대신 kubectl 클라이언트가 직접 API 서버에 스케일링을 요청하여 롤링 업데이트를 수행함으로써 쿠버네티스의 "선언적" 체계와 대척한다. rolling update 도중 kubectl의 네트웍이 끊어진다면 update는 그 상태에서 중단되고 새 버젼과 구 버젼의 pod 가 혼재하는 끔찍한 혼종이 남는다.
ReplicationController의 한계
앞서 "rolling-update" 명령은 deprecate 하여 더이상 쓸 수 없다고 했다. 그럼 ReplicationController(이하 rc)의 명세를 수정하면 rolling update를 수행할 수 있을까?
/*
* kubia pod는 웹 요청을 받으면 자신의 API version을 반환한다.
*/
// 1. rc/kubia-v1의 image 변경
$ kubectl set image rc kubia-v1 nodejs=sonientaegi/kubia-v2
// 2. rc/kubia-v1의 명세 조회
$ kubectl describe rc/kubia-v1
---------------------------------------------------------
Name: kubia-v1
{...}
Pod Template:
Labels: app=kubia
Containers:
nodejs:
Image: sonientaegi/kubia-v2
{...}
// 3. curl 수행 결과
API version V1 : kubia-v1-kvsgl
API version V1 : kubia-v1-b4kbc
API version V1 : kubia-v1-qslmv
{...}
kubectl set image 명령으로 kubia-v1의 명세에서 nodejs 컨테이너의 이미지를 sonientaegi/kubia-v1에서 sonientaegi/kubia-v2로 변경하였다. 하지만 pod를 구성하는 nodejs 컨테이너는 갱신되지 않았고 여전히 API version V1이 호출되고 있다. rc는 replica, 즉 pod를 관리할 뿐 자체적으로 pod의 컨테이너를 갱신하지 않는다.
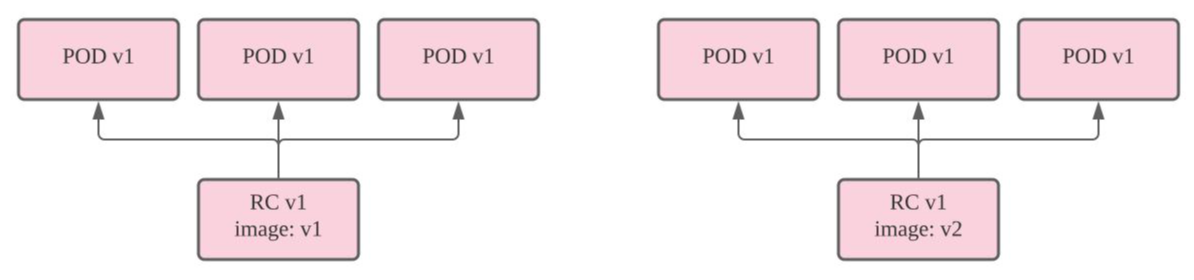
실제로 "rolling-update" 명령은 rc의 명세를 바꾸는게 아니라...
- 새로운 rc kubia-v2를 만든 뒤
- kubia-v2에서 N개의 pod를 만들고
- 기존의 rc인 kubia-v1에서 N개의 pod를 삭제하는걸 반복하여
- 모든 pod를 교체(또는 제거)한뒤
- 최종적으로 kubia-v1을 삭제함
으로써 rolling update를 종료한다.
디플로이먼트를 이용한 선언적 업데이트
결국 명세를 통한 선언적 업데이트를 수행하기 위해서는 rc를 관리하기 위한 상위 수준의 자원이 필요하다. 최신의 k8s에서는 Deployment(이하 deploy)가 이를 수행하고 있다.
// deploy가 관리하는 명세
apiVersion: apps/v1 # apps/v1beta1 > v1 으로 변경
kind: Deployment
metadata:
name: kubia
spec:
replicas: 3
selector: # 추가
matchLabels: # 추가
app: kubia # 추가
template:
metadata:
name: kubia
labels:
app: kubia
spec:
containers:
- image: sonientaegi/kubia:v1
name: nodejs
---
# 서비스 관련 명세
{...}위는 sonientaegi/kubia:v1 이미지를 실행하는 / nodejs로 명명한 컨테이너로 구성된 / pod 사본 3개를 관리하는 / deployment의 spec 이다. 별도로 명시가 되어있지 않지만 이 명세는 ReplicationSet(이하 rs)를 포함하고 있으며 배포 단계에서 자동적으로 rs가 추가되어 deploy - rs - pod[3] 순으로 클러스터를 구성한다. 그리고 deploy가 원할한 업데이트가 이루어지도록 통제한다.
Deployment와 관련한 명령
kubectl delete {resource}/{name}
해당 자원을 삭제한다.
kubectl delete {resource} --all
모든 자원을 삭제한다.
kubectl create -f {manifest file} --record
지정한 파일에 기술한 스팩을 이용하여 "선언적"으로 클러스터를 생성한다. --record를 명시해야 개정 이력 관리가 가능하다.
kubectl rollout status {resource}/{name}
롤아웃 진행 상태를 연속하여 출력하며 디플로이가 종료하면 함께 종료한다.
Deployment 수행 결과
Spec에 명시하지 않았지만, Deployment를 이용하면 pod를 관리하는 Replica Set을 생성하고 rs가 pod를 관리한다.
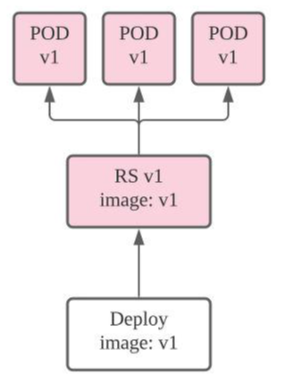
그리고 pod의 이름은 {deploy name}-{rs hash}-{pod hash} 형태로 구성하여 종속 관계를 표시한다.
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
kubia 3/3 3 3 11m
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
kubia-85bbc98669 3 3 3 11m
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kubia-85bbc98669-74hb9 1/1 Running 0 3m53s
kubia-85bbc98669-dhk2m 1/1 Running 0 3m54s
kubia-85bbc98669-hj8b4 1/1 Running 0 3m51sPOD 업데이트
Deployment를 이용하면 deploy의 스펙(또는 pod template)을 변경함으로써 선언적으로 pod를 업데이트 할 수 가 있다. 쿠버네티스는 선언적 명령체계를 지향하며, deploy의 스펙을 변경하기만 하면 사용자가 별도의 처리를 하지 않아도 k8s가 업데이트 한 정의와 일치하기 위하여 필요한 자원을 재배포하는 단계를 수행한다.
Deployment 스펙 변경 명령
kubectl edit deploy {name}
현재 k8s에 반영하고 있는 manifest를 직접 수정할 수 있다. 처음 deploy 할때 사용한 파일이 아니라, 이를 참고하여 k8s에서 최종적으로 구성한 manifest이다. 따라서 변경 후 저장해도 원본 manifest 파일에 영향을 주지 않는다.
kubectl patch deploy {name} -p '{JSON formatted spec description}'
전체 스펙 중 입력한 항목만 변경한다. 스펙의 일부를 CLI로 변경할때 유용하다.
kubectl set image {resource} {name} {container name}={image}
지정한 컨테이너의 image를 교체한다.
예 : kubectl set image deploy kubia nodejs=sonientaegi/kubia:v2
kubectl apply -f {manifest file} --record
kubectl create ... 로 deployment 할 때와 동일하게 manifest file을 적용한다.
kubectl apply -f 를 이용하여 스펙을 변경한다면 object 단위 갱신을 한다. 만약 pod 템플릿에 추가 container를 지정한다면 k8s는 이를 포함하는 새 pod를 생성한다. 반대로 기존에 존재하는 복수의 conainter 중 하나를 pod 템플릿에서 제거한다면 k8s는 이를 제거한 새 pod를 생성한다. service에 포트를 추가하는 경우도 이와 마찬가지로 동작한다.
만약 ".spec.strategy.type==Recreate"을 명시하지 않으면 기본적으로 RollingUpdate 전략을 따른다.

POD 원복
위 RollingUpdate 개념도에서 모든 pod를 업데이트 한 상태를 주목해본다. k8s는 pod와는 대조적으로 더이상 필요 없어진 RS v1을 삭제하지않고 가용한 pod 개수만 0으로 변경한다.
NAME DESIRED CURRENT READY AGE
kubia-7c98c94cb 3 3 3 18m
kubia-7fd5745f4f 0 0 0 20m
kubia-85bbc98669 0 0 0 23m만약 배포에 문제가 있어 원복을 하거나 롤아웃을 중단해야하는 경우, 다시 spec을 수정하거나, deploy & rs를 만드는 과정이 불필요 하며 undo 명령으로 간단히 해결할 수 있다. undo 명령은 대기 중인 rs의 가용한 pod 개수를 원래대로 돌림으로써 신속하게 원복을 수행한다.
kubectl rollout undo deploy {name} [--to-revision={revision}]
deployment의 상태를 바로직전으로 롤백한다. 옵션으로 특정 revision을 지정할 수 있다. 개정 이력은 rollout history 명령을 사용하여 조회할 수 있다.
kubectl create/apply 수행 시 --record를 추가한 경우에만 변경 이력을 확인할 수 있다. 특정 revision으로의 rollback은 --record와 무관하게 가능한다. 따라서 rs를 수작업으로 지우는 행위는 지양한다.
롤아웃 제어
속도제어
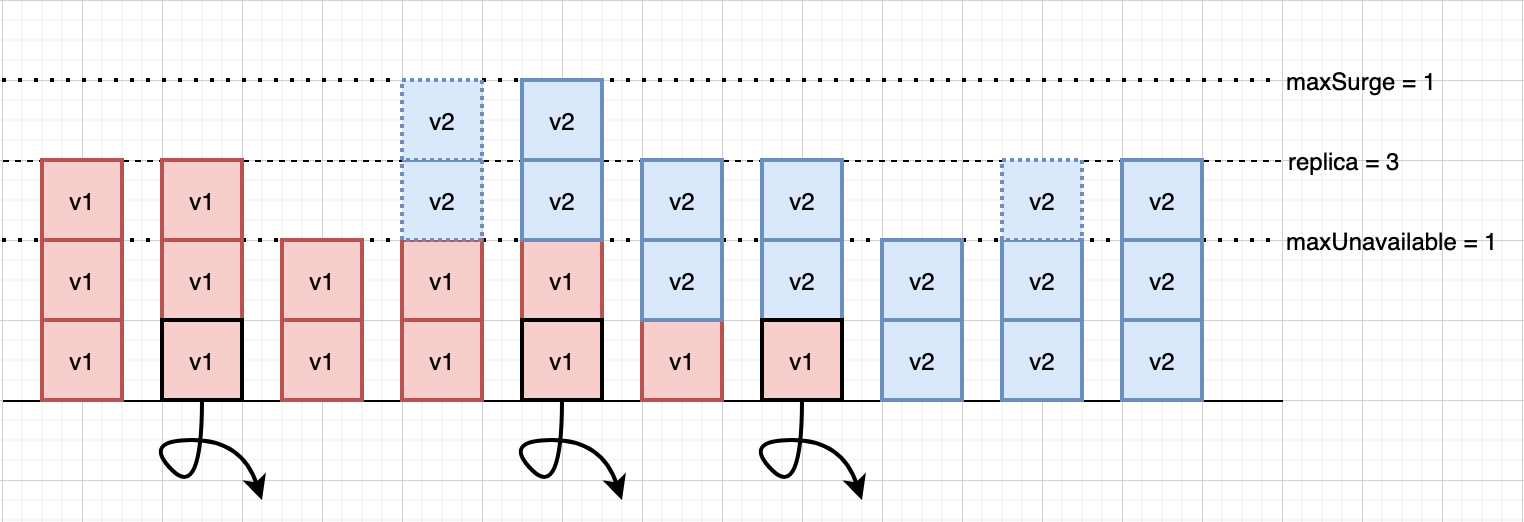
RollingUpdate는 일부 pod를 지우고 생성하기를 반복하여 최종적으로 전체 pod를 갱신하는 방식이다. 한번에 생성 가능한 pod의 개수를 조절함으로써 rollout을 빠르게 또는 느리게 완료할 수 있는데 k8s에서는 교체가능한 pod의 개수를 직접 지정하는 대신, 허용 가능한 오차 개수를 선언함으로써 k8s가 유동적으로 pod를 교체 할 수 있도록 한다. 이와 관련한 설정값은 세가지이다.
- replica - 목표하고자 하는 pod replica의 개수.
- maxUnavailable - replica를 기준으로 최대 불용 pod 개수.
- maxSurge - replica를 기준으로 최대 초과 pod 개수.
위 값을 기준으로 pod를 삭제, 생성하기를 반복하여 모든 pod를 업데이트 한다.
- replica - maxUnavailable (최소 허용 pod 개수) 내에서 최대한 기존 pod를 제거한다.
- replica + maxSurge (최대 허용 pod 개수) 내에서 최대한 새 pod를 생성한다. 단 새 pod의 개수는 replica를 넘지 않는다.
- 기존 pod를 제거하여 replica 개수를 맞춘다.
- 모든 pod를 업데이트 할 때 까지 1번부터 반복한다.
{...}
spec:
replicas: 3
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
{...}
만약 maxSurge와 maxUnavailable의 값이 0이면 어떤 일이 벌어질까? 기존 pod를 지울 수도, 새로운 pod를 만들 수 도 없으니 사용자가 임의로 특정 pod를 삭제하기 전 가지 rollout은 stuck에 걸릴것이다. 다행히 k8s는 이를 미리 감지하여 오류를 반환한다.
The Deployment "{name}" is invalid: spec.strategy.rollingUpdate.maxUnavailable: Invalid value: intstr.IntOrString{Type:0, IntVal:0, StrVal:""}: may not be 0 when `maxSurge` is 0
동작 제어
k8s는 필요에 따라 rollout을 일시 정지 하거나 속행할 수 있는 기능을 제공한다.
kubectl rollout pause deploy {name}
rollout을 멈춘다.
kubectl rollout resume deploy {name}
rollout을 속행한다.
일시 정지 상태에서 undo를 수행하면 deploy를 취소할 수 있다. 이런 식으로 pause와 resume을 이용하면 카나리 릴리스나 A/B 테스트를 수행할 수 있다.
오류 제어
readiness 란 container가 정상적으로 서비스를 제공할 준비가 되었는지의 여부로 실패할 경우 pod를 서비스에서 배제한다. k8s는 readinessProbe를 이용하여 오류를 판별하고 rollout을 제어할 수 있다. pod 생성 후 minReadySeconds 경과 후 pod의 상태가 이때 pod를 삭제하거나 undo를 수행하지 않으며 이후 .spec.progressDeadlineSeconds 이 경과하면 error 보고를 하고 대기한다.
참고.
beta 시절에는 자동으로 undo를 수행하였으나 apps/v1에서는 명시적으로 undo를 하지 않으면 계속 대기한다.
다음의 예제로 살펴보자. 먼저 app.js는 첫 5번째 요청까지만 처리하고 6번째 요청 부터는 500 reponse를 반환한다.
// app.js
const http = require('http');
const os = require('os');
console.log("Server starting");
var requestCount = 0;
var handler = function (request, response) {
console.log(request.connection.remoteAddress);
if (++requestCount >= 6) {
response.writeHead(500);
response.end("WTF : " + os.hostname() + "\n");
return;
}
response.writeHead(200);
response.end("API version vFail : " + os.hostname() + "\n");
};
var www = http.createServer(handler);
www.listen(8080);그리고 8080 포트로 매초마다 요청을 날리는 readinessProbe를 추가한다.
{...}
spec:
replicas: 3
minReadySeconds: 10 # 새로 pod 생성 후 minReadySeconds 동안 대기
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
{...}
template:
{...}
spec:
containers:
- image: sonientaegi/kubia:vFail
name: nodejs
readinessProbe:
periodSeconds: 1
httpGet:
path: /
port: 8080
{...}이 명세를 이용한 RollingUpdate는 다음과 같은 순서대로 수행 후 실패한다.
- 기존 pod를 제거한다 (#2).
- 새로운 pod를 생성 후 readinessProbe 체크가 성공하여 pod는 READY 상태가 된다 (#4~#5).
- pod를 서비스에 투입한다. 이 시점에 쿼리를 날려보면 새 API 버젼을 반환한다 (#5~#6).
- 계속하여 매초 마다 readinessProbe를 수행한다. 6번째 요청 부터는 실패한다 (#7).
- pod가 UNREADY 상태이므로 서비스에서 배제한다 (#7).
- minReadySeconds 경과 후에도 pod는 UNREADY 상태를 유지하므로 rollout은 계속 대기한다 (#8).
- 이후 타임아웃 시간이 경과하면 오류 로그를 남기고 rollout은 계속 대기한다.

이 상태는 kubectl를 이용해 조회할 수 도 있다.
rollout 상태 조회
$ kubectl rollout status deploy kubia
Waiting for deployment "kubia" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 2 out of 3 new replicas have been updated...
// 10분 경과 후
error: deployment "kubia" exceeded its progress deadline
rs 상태 조회
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
kubia-8454f9f687 3 3 3 86s
// rollout 개시!
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
kubia-6cf8d47ccb 2 2 2 5s
kubia-8454f9f687 2 2 2 105s
// 11초 경과 후 새 rs의 pod를 서비스에서 배제함.
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
kubia-6cf8d47ccb 2 2 1 11s
kubia-8454f9f687 2 2 2 111s
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
kubia-6cf8d47ccb 2 2 0 17s
kubia-8454f9f687 2 2 2 117s
// 타임아웃 후에도 rollout은 대기 상태를 유지한다.
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
kubia-6cf8d47ccb 2 2 0 11m
kubia-8454f9f687 2 2 2 13m
pod 상태 조회
// rollout 개시!
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kubia-6cf8d47ccb-gp9r4 1/1 Running 0 3s
kubia-6cf8d47ccb-psnpk 1/1 Running 0 3s
kubia-8454f9f687-gxtf9 1/1 Running 0 1m43s
kubia-8454f9f687-jkrj4 1/1 Running 0 1m43s
// 8초 후 readinessProbe Fail.
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kubia-6cf8d47ccb-gp9r4 0/1 Running 0 8s
kubia-6cf8d47ccb-psnpk 0/1 Running 0 8s
kubia-8454f9f687-gxtf9 1/1 Running 0 1m48s
kubia-8454f9f687-jkrj4 1/1 Running 0 1m48s
// minReadySeconds 경과 후 다음 update 진행 불가.
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kubia-6cf8d47ccb-gp9r4 0/1 Running 0 17s
kubia-6cf8d47ccb-psnpk 0/1 Running 0 17s
kubia-8454f9f687-gxtf9 1/1 Running 0 1m57s
kubia-8454f9f687-jkrj4 1/1 Running 0 1m57s
// rollout 타임아웃.
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kubia-6cf8d47ccb-gp9r4 0/1 Running 0 11m
kubia-6cf8d47ccb-psnpk 0/1 Running 0 11m
kubia-8454f9f687-gxtf9 1/1 Running 0 13m
kubia-8454f9f687-jkrj4 1/1 Running 0 13m
readinessProbe에 관해서는 아래에서 더 다루어 본다.
[쿠버네티스 인 액션] 09. rollout과 readinessProbe
클러스터를 구성하는 container가 생성 즉시 가용상태가 된다고 보장할 수 없다. 어떤 container는 만듬과 동시에 가용할 수도 있고, 어떤 container는 일정 시간이 경과해야 가용할 수 도 있다. 또 다른
sonien.tistory.com
'개발 > 구름' 카테고리의 다른 글
| [쿠버네티스 인 액션] 09. rollout과 readinessProbe (0) | 2021.07.16 |
|---|---|
| [쿠버네티스 인 액션] 01. 쿠버네티스 소개 (0) | 2021.06.28 |